























.webp?width=250&height=131&name=how-to-use-gdms-q1-2024%20(1).webp)
















You’re working on a report, suddenly half way through your data input, the screen freezes and with it the ability to save or retrieve your work. You sit there, frantically watching your unsaved work disappear, and just like that, Microsoft sends off an error message that your “program ended unexpectedly”. You can say that again. Too often we’ve all experienced this. Fortunately, companies like Microsoft have developed a series of recovery options that help ease program interruptions and the loss of unsaved data. Just like this scenario, system failures anywhere are inevitable and that’s why developing a backup and failover solution is critical to any business.
No matter how meticulous the process of engineering a good product or system can be, sometimes it’s hard to prevent hardware or software malfunction. That doesn’t mean that the aftermath of interrupted systems or data has to be chaotic. Anticipating failures and developing a backup and failover solution is the first step in preventing disastrous downtime.
Backup Solutions
Software companies like Microsoft for example have a standard backup solution when a program crashes and users lose their work. Systems automatically generate temporary files which are updated every few minutes when a new file is created. This is called a back-up solution and it allows users to access a copy of their unsaved files.
In more complex scenarios, business need to create their own backup solutions. For example, when using remote or local database servers to access and exchange data. It’s important to have a plan in place in the event of servers going down. To figure out the exact frequency a system should be backed up, experts recommend having a RTO (Recovery Time Objective) meaning the time it would get your database up and running after it fails as well as RPO or Recovery Point Objective which refers to the maximum acceptable amount of data loss measured in time. The combination of RTO and RPO will yield a customized backup solution that fits your specific needs.
Failover Solutions
The next piece of the puzzle is a failover solution, or the operational process of switching to a secondary server when the primary server fails. Here at Grandstream, we understand the urgency to be prepared for system failures, which is why we developed a failover solution for unified communication systems. We call it HA100, a High Availability Controller that works with our UCM6510 IP PBX system.
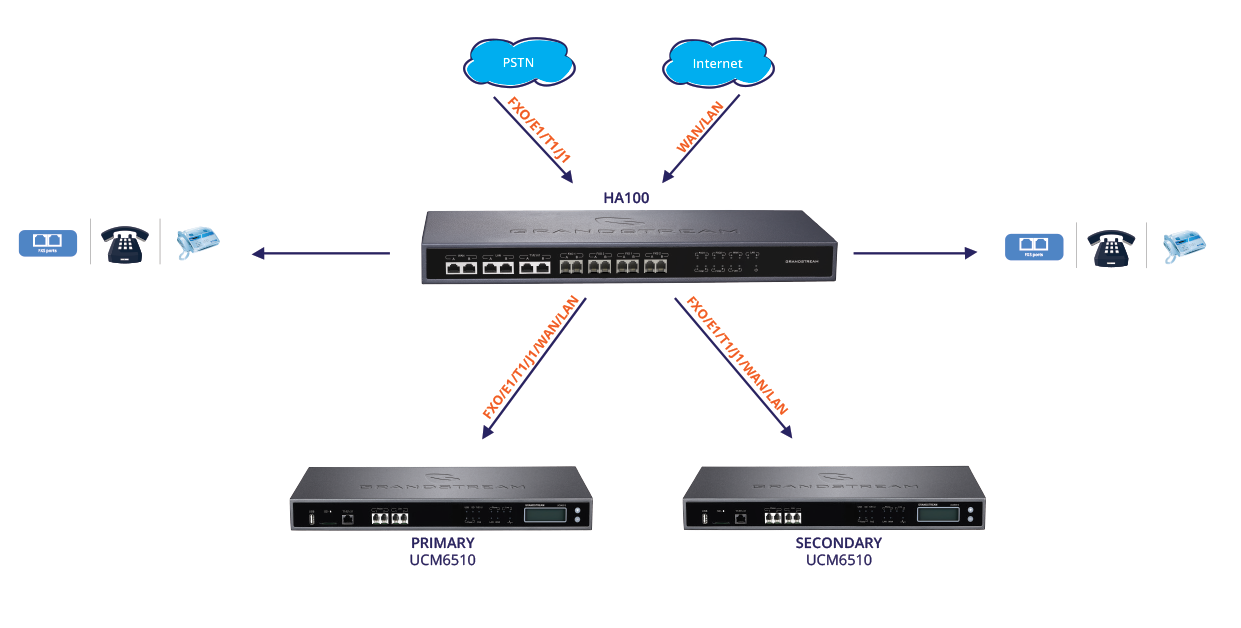
Its concept is simple: the HA100 serves as a connector for two UCM6510’s. When the main UCM fails, the HA100 automatically switches the system control (and all components connected to it) to the second UCM. Depending on the number of SIP accounts registered to the UCM6510, the whole switching process can take no longer than 50 seconds. One of the reasons why the HA100 is so reliable is because it’s not a computer with a full running processor which make it susceptible to failures, but rather a switch whose only job is to switch the failed server to the backup. Making it a virtually fast and automatic solution for your unified communications.
No longer is the downtime of system failures have to be a mess. By setting up backup and failover solutions for your systems, your business can stay ahead of the game even when failures are inevitable.
If you want to learn more about our UC failover solution, click below to start.
